day 15- k-means clustering
day 15-
k-means clustering
السلام عليكم ورحمة الله... معاكم Kaito :)
مرحبا بيكم فالنهار 15 ديال سلسلة 30 يوم من التعلم الآلي..
وصلنا للنصف ديال challenge
ماشاء الله اللهم بارك
دوزنا 15 يوم.. بقات 15 يوم وحدة اخرى
ان شاء الله تدوز ونساليو وحنا فاهمين هاد الأي أي
ملي شفنا اهم الخوازميات الخاضعة لاشراف supervised
اليوم غنشوفو unsupervised
وغنبداو بواحد الالغوريتم اللي كيبان صعيب
ولكن فالحقيقة راه بطاطا
اللي هو k-means clustering

هو واحد النوع من خوارزميات التعلم الالي الغير خاضعة لاشراف
unsupervised machine learning algorithm
وهاد النوع هو اللي كنخدمو فاش كتكون الداتا ديالنا unlabeled
يعني مكنتدخلوش فالقرار او مكنعطيوش معلومات للمودل
وهنايا الهدف ديال k-means هو نلقاو مجموعات groups فالداتا
او كيتسماو "clusters" .. بالعربية "عناقيد"
(هي نيت منين جات k-means clustering)
هاد الالغوريتم كيحل المشاكل ديال تصنيف الداتا
من خلال عدد معين من clusters (داك العدد هو k)
فالاول ملي كنت كنعطي للمودل تصاور ديال المشاش والكلاب
كنت كنقول ليه راه هادو مشاش وكلاب
هنايا فهاد النوع ديال الخوارزميات … مكتقوليه والو
كتعطيه غير التصاور مخلطين
وكتقول ليه قاد ليا المجموعات او العناقيد اللي كيبانو ليك
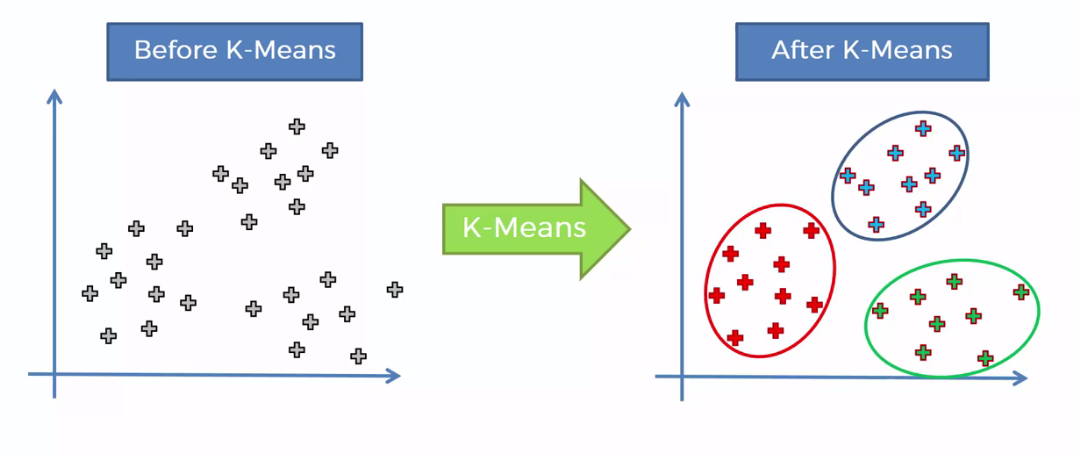
انفهمو دبا الكونصبت ديالها:

أول حاجة قبل منقسمو الداتا الى مجموعات
خصنا نختارو العدد ديال العناقيد clusters..
اللي هو العدد k..
كتختار عشوائيا واحد العدد k ديال النقط فالمعلم..
هاد النقط كيتسماو centroids أو النقطة الوسطى للعنقود
وماشي ضروري يكونو من نقط البيانات اللي عندك
تقدر تكون اي نقطة باغي فداك المعلم الاختيار راه عشوائي
من بعد كتشد دوك النقط كاملين اللي عندك فالداتا وكتصنفهوم مع أقرب centroid ليهم..
(كتحسب المسافة بيناتهم واللي قريبة كتولي منهم)
ملي كدير الخطوة الثالثة كيتكونو ليك مجموعات clusters
دوك النقط centroids اللي ختاريتي فالاول كيمشيو
وكتعاود تحسب وتختار النقطة الوسطى centroid ديال كل مجموعة cluster
فاش كيبانو دوك النقاط الوسطى الجداد ،
كنعاودو نطبقو الخطوة 3 و 4. بحيث كتقلب على أقرب مسافة لكل نقطة بيانات من النقاط الوسطى الجديدة وكتربطها مع k العناقيد الجديدة.
كتبقا تعاود هاد العملية وكتحبس ملي النقط الوسطى مكيتبدلوش.
كيبان ليا بغيتي مثال ههه
غنعطيك اسيدي ا لالة المثال..
نفتارضو عندنا هاد الgraph
وبغينا نطبقو k-means باش نجمعو كل عينة ف cluster

اول خطوة قلنا خصنا نختارو عدد الclusters اللي هو k
باش نسهلو هاد المثال عليكم نختارو مثلا k=2
الخطوة الثانية هي نختارو عشوائيا k نقط اللي غيكونو centroids
ديجا عندنا k=2 اذن غناخدو 2 نقط عشوائيين من graph
كيما كتشوفو لونت كل وحدة بالحمر والاخضر باش نفرق كل مجموعة.

هنايا كتجي الخطوة الثالثة:
كل نقطة من نقط البيانات اللي عندنا كنصنفها مع اقرب centroid ليها
نورمالمون كنحسبو المسافة ما بين كل نقطة ودوك المربعات الملونين
ولكن غنخدمو بواحد الطريقة اللي أسهل وغتكون شفتيها ديجا فالثانوي
(الا ايلا كنتي كتنعس فالحصة ديال الماط)
غنرسمو خط مستقيم بين النقطتين المركزيتين centroids ،
وكنرسمو واحد الخط متعامد فمنتصف الخط المستقيم.

من هاد القسمة كيسهال علينا البلان..
أي نقطة كاينة فوق داك المستقيم راه قريبة للمربع الازرق
واي نقطة كاينة التحت راه قريبة للمربع الاحمر
صافي كنلونو النقط على حسب centroid ديالها بنفس اللون

فهاد المثال.. حسبنا المسافة بين النقط باستعمال المسافة الاقليدية
خدمنا بيها هنا غير حيت واضحة و ديجا شفناها فالايام اللي دازو
وماشي بوحدها اللي كاينة.. يقدر يكون ما احسن
وهادي هي الخدمة ديال عالم البيانات data scientist
باش يلقا أحسن method لكل حالة..
هنايا كتجي الخطوة الرابعة..
وهي انه كتقلب على النقط الوسطى الجداد لكل مجموعة cluster
اعتبر هاد النقط الوسطى centroids هما مركز الثقل ديال clusters ديالك
فالشيما ديالنا كيكحازو centroids ديالنا باش يجيو فالوسط ديال كل مجموعة

هنايا كتعاود الخطوات اللونين.. كل نقطة كتعطيها centroid ديالها
كتقسم وكتلقا بلي واحد النقطة حمرا دخلات دبا للمجال الازرق
وجوج زرقين دخلو للمجال الاحمر

اللي فالمنطقة الزرقا كيولي ازرق
اللي فالمنطقة الحمرا كيولي حمر
(اللي طاح فالمقلا يتقلا)

وكنبقاو نعاودو الخطوات
كنردو centroid فمركز ثقل المجموعة ديال النقط الجديدة

وكتعاود تقسم..

وكتبدل الالوان ديال النقط..

ونتا غادي بحال هكا كتعاود الخطوات..




حتى كتوصل لهنا..

هنايا معندك متبدل
ملي كتقسم و كتلقا كل نقطة ديجا فبلاصتها
صافي كتكون ساليتي الخطوات ديالك وسالا الالغوريتم
فالاخر كيعطيك 2 ديال clusters
المودل ديالك راه واجد..

دبا السؤال اللي غيجي فبالكم
هو كيفاش غدي نعرف هاد العدد k اللي كنختار فالاول
كاينين طرق باش تختار أحسن k
غندوي على الطريقة المشهورة والساهلة
واللي هي "طريقة الكوع" elbow method
طريقة الكوع هي تقنية كتعاونا باش نلقاو العدد الأمثل للمجموعات في مجموعات K-means.
الفكرة هي انك كتخدم الالغوريتم ديالك شحال من مرة على قيم مختلفة من k
(مثلا كتدير k من 1 إلى 10)،
ولكل قيمة k كيعطيك الالغوريتم واحد القيمة ديال الخطأ.
كتسمى مجموع الأخطاء المربعة (SSE).
هاد القيمة كتعاونك باش تعرف الاداء ديال الالغوريتم
وباش تحسن من داك الاداء خص تنقص من نسبة الخطأ

"الكوع" هو ديك النقطة التي تمثل k الأفضل والامثل.
هاد النقطة هي فين كيبدا المؤشر SSE فالتسطيح
وكيشكل واحد شكل كيشبه للمرفق.
صافي كنختاروها باش تولي k ديالنا (k=3)
هادا بكل بساطة هو k-means clustering

هاد الحساب وهاد الرياضيات اللي شفتي هنايا كامل
راه ماشي نتا لي كديرو
فالكود كتعيط على method سميتها KMeans
كتعطيها الداتا والعدد k
صافي.. هدا هو جهدك والباقي عليها..
ايلا كنتي ديجا كتكودي وباغي تطبق هاد الالغوريتم فداتاسيت بصح
(متخافش مافيه لا ماط لا والو..)
تبع مع هاد المقال فيه خطوات بالكود كوبيهم وخدمهم وراك ناضي
هذي خلاصة اليوم..
نتلاقاو فايمايل اخر غدا!
كنتمنى تكونو استافدتو.. ايلا عندكم شي تساؤل اولا مشرحتش شي حاجة مزيان، غير صيفط ليا رد فهاد المايل نيت..
— Kaito
ملاحظات:
مصادر:
K-means Clustering (refresher)
ايلا عاجبك هدشي وقادر باش تساند هاد newsletter بدعم مادي
دخل لهنا: https://ko-fi.com/callmekaito
شكرا (:

السلام عليكم ورحمة الله... معاكم Kaito :)
مرحبا بيكم فالنهار 15 ديال سلسلة 30 يوم من التعلم الآلي..
وصلنا للنصف ديال challenge
ماشاء الله اللهم بارك
دوزنا 15 يوم.. بقات 15 يوم وحدة اخرى
ان شاء الله تدوز ونساليو وحنا فاهمين هاد الأي أي
ملي شفنا اهم الخوازميات الخاضعة لاشراف supervised
اليوم غنشوفو unsupervised
وغنبداو بواحد الالغوريتم اللي كيبان صعيب
ولكن فالحقيقة راه بطاطا
اللي هو k-means clustering
هو واحد النوع من خوارزميات التعلم الالي الغير خاضعة لاشراف
unsupervised machine learning algorithm
وهاد النوع هو اللي كنخدمو فاش كتكون الداتا ديالنا unlabeled
يعني مكنتدخلوش فالقرار او مكنعطيوش معلومات للمودل
وهنايا الهدف ديال k-means هو نلقاو مجموعات groups فالداتا
او كيتسماو "clusters" .. بالعربية "عناقيد"
(هي نيت منين جات k-means clustering)
هاد الالغوريتم كيحل المشاكل ديال تصنيف الداتا
من خلال عدد معين من clusters (داك العدد هو k)
فالاول ملي كنت كنعطي للمودل تصاور ديال المشاش والكلاب
كنت كنقول ليه راه هادو مشاش وكلاب
هنايا فهاد النوع ديال الخوارزميات … مكتقوليه والو
كتعطيه غير التصاور مخلطين
وكتقول ليه قاد ليا المجموعات او العناقيد اللي كيبانو ليك
انفهمو دبا الكونصبت ديالها:
أول حاجة قبل منقسمو الداتا الى مجموعات
خصنا نختارو العدد ديال العناقيد clusters..
اللي هو العدد k..
كتختار عشوائيا واحد العدد k ديال النقط فالمعلم..
هاد النقط كيتسماو centroids أو النقطة الوسطى للعنقود
وماشي ضروري يكونو من نقط البيانات اللي عندك
تقدر تكون اي نقطة باغي فداك المعلم الاختيار راه عشوائي
من بعد كتشد دوك النقط كاملين اللي عندك فالداتا وكتصنفهوم مع أقرب centroid ليهم..
(كتحسب المسافة بيناتهم واللي قريبة كتولي منهم)
ملي كدير الخطوة الثالثة كيتكونو ليك مجموعات clusters
دوك النقط centroids اللي ختاريتي فالاول كيمشيو
وكتعاود تحسب وتختار النقطة الوسطى centroid ديال كل مجموعة cluster
فاش كيبانو دوك النقاط الوسطى الجداد ،
كنعاودو نطبقو الخطوة 3 و 4. بحيث كتقلب على أقرب مسافة لكل نقطة بيانات من النقاط الوسطى الجديدة وكتربطها مع k العناقيد الجديدة.
كتبقا تعاود هاد العملية وكتحبس ملي النقط الوسطى مكيتبدلوش.
كيبان ليا بغيتي مثال ههه
غنعطيك اسيدي ا لالة المثال..
نفتارضو عندنا هاد الgraph
وبغينا نطبقو k-means باش نجمعو كل عينة ف cluster
اول خطوة قلنا خصنا نختارو عدد الclusters اللي هو k
باش نسهلو هاد المثال عليكم نختارو مثلا k=2
الخطوة الثانية هي نختارو عشوائيا k نقط اللي غيكونو centroids
ديجا عندنا k=2 اذن غناخدو 2 نقط عشوائيين من graph
كيما كتشوفو لونت كل وحدة بالحمر والاخضر باش نفرق كل مجموعة.
هنايا كتجي الخطوة الثالثة:
كل نقطة من نقط البيانات اللي عندنا كنصنفها مع اقرب centroid ليها
نورمالمون كنحسبو المسافة ما بين كل نقطة ودوك المربعات الملونين
ولكن غنخدمو بواحد الطريقة اللي أسهل وغتكون شفتيها ديجا فالثانوي
(الا ايلا كنتي كتنعس فالحصة ديال الماط)
غنرسمو خط مستقيم بين النقطتين المركزيتين centroids ،
وكنرسمو واحد الخط متعامد فمنتصف الخط المستقيم.
من هاد القسمة كيسهال علينا البلان..
أي نقطة كاينة فوق داك المستقيم راه قريبة للمربع الازرق
واي نقطة كاينة التحت راه قريبة للمربع الاحمر
صافي كنلونو النقط على حسب centroid ديالها بنفس اللون
فهاد المثال.. حسبنا المسافة بين النقط باستعمال المسافة الاقليدية
خدمنا بيها هنا غير حيت واضحة و ديجا شفناها فالايام اللي دازو
وماشي بوحدها اللي كاينة.. يقدر يكون ما احسن
وهادي هي الخدمة ديال عالم البيانات data scientist
باش يلقا أحسن method لكل حالة..
هنايا كتجي الخطوة الرابعة..
وهي انه كتقلب على النقط الوسطى الجداد لكل مجموعة cluster
اعتبر هاد النقط الوسطى centroids هما مركز الثقل ديال clusters ديالك
فالشيما ديالنا كيكحازو centroids ديالنا باش يجيو فالوسط ديال كل مجموعة
هنايا كتعاود الخطوات اللونين.. كل نقطة كتعطيها centroid ديالها
كتقسم وكتلقا بلي واحد النقطة حمرا دخلات دبا للمجال الازرق
وجوج زرقين دخلو للمجال الاحمر
اللي فالمنطقة الزرقا كيولي ازرق
اللي فالمنطقة الحمرا كيولي حمر
(اللي طاح فالمقلا يتقلا)
وكنبقاو نعاودو الخطوات
كنردو centroid فمركز ثقل المجموعة ديال النقط الجديدة
وكتعاود تقسم..
وكتبدل الالوان ديال النقط..
ونتا غادي بحال هكا كتعاود الخطوات..
حتى كتوصل لهنا..
هنايا معندك متبدل
ملي كتقسم و كتلقا كل نقطة ديجا فبلاصتها
صافي كتكون ساليتي الخطوات ديالك وسالا الالغوريتم
فالاخر كيعطيك 2 ديال clusters
المودل ديالك راه واجد..
دبا السؤال اللي غيجي فبالكم
هو كيفاش غدي نعرف هاد العدد k اللي كنختار فالاول
كاينين طرق باش تختار أحسن k
غندوي على الطريقة المشهورة والساهلة
واللي هي "طريقة الكوع" elbow method
طريقة الكوع هي تقنية كتعاونا باش نلقاو العدد الأمثل للمجموعات في مجموعات K-means.
الفكرة هي انك كتخدم الالغوريتم ديالك شحال من مرة على قيم مختلفة من k
(مثلا كتدير k من 1 إلى 10)،
ولكل قيمة k كيعطيك الالغوريتم واحد القيمة ديال الخطأ.
كتسمى مجموع الأخطاء المربعة (SSE).
هاد القيمة كتعاونك باش تعرف الاداء ديال الالغوريتم
وباش تحسن من داك الاداء خص تنقص من نسبة الخطأ
"الكوع" هو ديك النقطة التي تمثل k الأفضل والامثل.
هاد النقطة هي فين كيبدا المؤشر SSE فالتسطيح
وكيشكل واحد شكل كيشبه للمرفق.
صافي كنختاروها باش تولي k ديالنا (k=3)
هادا بكل بساطة هو k-means clustering
هاد الحساب وهاد الرياضيات اللي شفتي هنايا كامل
راه ماشي نتا لي كديرو
فالكود كتعيط على method سميتها KMeans
كتعطيها الداتا والعدد k
صافي.. هدا هو جهدك والباقي عليها..
ايلا كنتي ديجا كتكودي وباغي تطبق هاد الالغوريتم فداتاسيت بصح
(متخافش مافيه لا ماط لا والو..)
تبع مع هاد المقال فيه خطوات بالكود كوبيهم وخدمهم وراك ناضي
هذي خلاصة اليوم..
نتلاقاو فايمايل اخر غدا!
كنتمنى تكونو استافدتو.. ايلا عندكم شي تساؤل اولا مشرحتش شي حاجة مزيان، غير صيفط ليا رد فهاد المايل نيت..
— Kaito
ملاحظات:
مصادر:
K-means Clustering (refresher)
ايلا عاجبك هدشي وقادر باش تساند هاد newsletter بدعم مادي
دخل لهنا: https://ko-fi.com/callmekaito
شكرا (:
التالي