day 25 - how do RNNs work?
السلام عليكم ورحمة الله... معاكم Kaito :)
مرحبا بيكم فالنهار 25 ديال سلسلة 30 يوم من التعلم الآلي..
شفنا البارح RNN
وشفنا كيفاش داير الشكل ديالها ولاش كتصلاح
اليوم غنشوفو كيفاش كتخدم وكتعالج البيانات اللي عندنا

كيما قريتو البارح
الشبكة العصبية المتكررة RNN
هي واحد الشبكة اللي كتاخد الداتا اللي تسلسلية sequential
باش تكون قادرة انها تطبق الذاكرة قصيرة المدى على ديك الداتا
وكتقدر "تحفظ" أجزاء من المدخلات وكتستعملهم باش تعطينا تنبؤات دقيقة.
دبا غنشوفو كيفاش كتخدم:
الشبكة العصبية العادية كتخدم بهاد الطريقة:
1. كناخدو مثال example من شي داتا سيت dataset.
2. الشبكة غاتاخد هاد المثال وتطبق عليه بعض الحسابات المعقدة
باستخدام متغيرات كيتحطو بشكل عشوائي
(هي الأوزان ايلا بقيتي عاقل).
3. غادي تعطينا الnetwork ف output النتيجة المتوقعة.
4. و ايلا درنا مقارنة هاد النتيجة بالقيمة الاصلية الحقيقية غتعطينا داك الخطأ error.
5. كنطبقو backpropagation باش يتضبطو المتغيرات weights.
6. كنبقاو نعاودو الخطوات من 1 إلى 5 حتى نكونو واثقين ونقولو بأن المتغيرات ديالنا محددة ومزيانة.
7. كنديرو التنبؤ من خلال تطبيق هاد المتغيرات على مدخلات جديدة معمرنا مشفناها Test data.
الشبكات العصبية المتكررة RNN حتا هما عندهم بروسيس مشابه،
ولكن باش تفهم الفرق بيناتهم،
غادي نمرو على أبسط نموذج MODEL نقدو نقادو
واللي كيدير التنبؤ بالكلمة التالية ف تسلسل كيعتمد على الكلمات السابقة.
بحال ايلا قلتي لشات جي بي تي.. "كمل ليا هاد الجملة بما يناسب"
أولاً، غادي نحتاجو ندربو الشبكة باستخدام مجموعة بيانات كبيرة.
وفالمثال الذي عندنا..
نقدرو نختارو أي نص كبير (مثلا الكتاب التاريخي "الحرب والسلام" لليو تولستوي).
ملي كنساليو من التدريب TRAINING،
كنجربو ندخلو جملة "كان نابليون إمبراطور ..."
باش نتوقعو تنبؤ معقول بناءً على المعلومات اللي كاينة ف الكتاب.
إذا كيفاش كنبداو؟
كيما شفنا فالخطوات اللي الفوق،
كندخلو مثال واحد ف كل مرة وكننتجو نتيجة واحدة،
وبجوجهم عبارة عن كلمة واحدة.
الاختلاف اللي كيبان بين RNN و بين الشبكة العصبية الاصطناعية
هو انه هنايا غادي نحتاجو أيضًا أننا نعرفو شكاين على المدخلات السابقة قبل تقييم النتيجة.
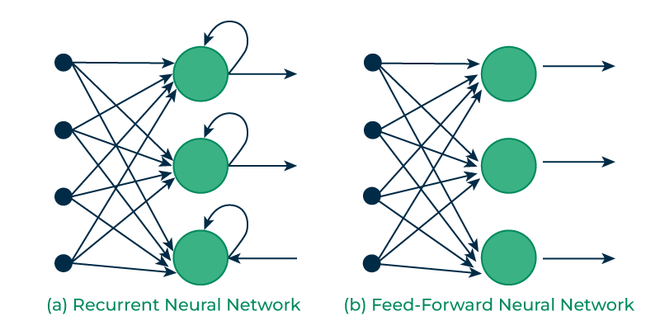
هنايا تقدر انك تخيل هادوك RNNs بحال شبكات عصبية متعددة التغذية،
كيما قلنا البارح "كتاكل راسها"
وكتدوز المعلومات من شبكة إلى أخرى.
شوف معايا هاد الشيما..
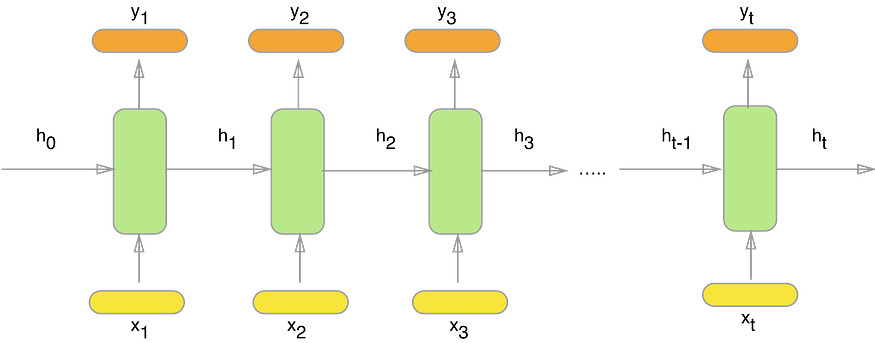
هنايا x_1، x_2، x_3، …، x_t هما الكلمات المدخلة من النص،
ديك y_1، y_2، y_3، …، y_t هما الكلمات التالية المتوقعة..
و h_0، h_1، h_2، h_3، …، h_t بحال ايلا قلتي كارط ميموار..
كتحتفظ بالمعلومات الخاصة بكلمات الإدخال السابقة.
نظرًا لأنه الشبكة العصبية مكتقبلش النص العادي حيت كتعامل غير بالارقام،
اذن غنحتاجو نديرو تشفير الكلمات إلى ارقام او متجهات.
هادي هي vectorization اللي دوينا عليها البارح..
وأفضل طريقة باش تدار هي استخدام تضمينات الكلمات word embeddings
وكنخدمو ب word2vec أو GloVe وغيرهم الكثير...
ولكن هدي غندويو عليها فنهار اخر
باش نديرو التدريب ديال البيانات كنستخدمو هاد القواعد الرياضية..
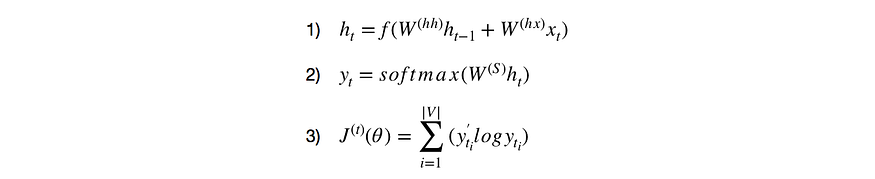
متخلعوش كل وحدة غنعطيو الاهمية ديالها فالحالة ديالنا
دوك W اللي كتشوف تما هادوك هما الاوزان Weights
ديك h_t كتهز معلومات حول الكلمات السابقة في التسلسل.
وكنحسبوها باستخدام متجه h_(t-1) اللي قبل منو
ومتجه الكلمة الحالي x_t.
دوك 2 متجهات كنديرو ليهم عملية الزائد وكنطبقو عليهم دالة التنشيط غير الخطية f (عادةً tanh أو sigmoid)
ديك y_t كتحسب متجه الكلمات المتوقع ف خطوة زمنية معينة t.
كنخدمو بواحد الدالة سميتها softmax باش نقادو متجه (V,1) يحتوي على جميع العناصر التي يصل مجموعها إلى 1.
وهاد التوزيع الاحتمالي كيعطينا فهرس الكلمة التالية اللي هي اقرب احتمال من المفردات.
هاد J كتحسب لينا واحد النوع من loss function سميتو
cross-entropy loss function ف كل خطوة زمنية
وهدشي باش نحسبو نسبة الخطأ بين الكلمة المتوقعة والفعلية.
فاش كنديرو الtraining ديالنا وكيصدق لينا الاوزان مزيانين،
كيجينا التنبؤ بالكلمة التالية ف الجملة "نابليون كان هو الإمبراطور ديال ..."
واحد الحاجة اللي بطاطا..
عندنا 5 كلمات وبغينا السادسة
ايلا دوزنا كل كلمة ف خطوة زمنية مختلفة من RNN
غيعطينا h_1، h_2، h_3، h_4.
ايلا بغينا الكلمة التالية اللي هي y_5
كنطبقو القاعدة اللولة والثانية باستعمال h_4 وx_5
(هاد x_5 هي متجه الكلمة الخامسة "ديال")
إذا كان التدريب ديالنا ناجح،
فيجب أن نتوقع أن مؤشر index ديال أكبر رقم في y_5
هو نفس مؤشر كلمة "فرنسا" في المفردات اللي عندنا.
وبالتالي غتعطيك فرنسا..
وهاهي الجملة سالات..
هادا هو البلان ديال RNNs
كيبان شوية صعيب.. ولكن الكونصبت ديالو راه غير تمثيل ل كيفاش كيفكر الدماغ ديالك
خلاصة اليوم:

نتلاقاو فايمايل اخر غدا!
كنتمنى تكونو استافدتو.. ايلا عندكم شي تساؤل اولا مشرحتش شي حاجة مزيان، غير صيفط ليا رد فهاد المايل نيت..
— Kaito
ملاحظات:
ايلا عاجبك هدشي وقادر باش تساند هاد newsletter بدعم مادي
دخل لهنا: https://ko-fi.com/callmekaito
شكرا (:

السلام عليكم ورحمة الله... معاكم Kaito :)
مرحبا بيكم فالنهار 25 ديال سلسلة 30 يوم من التعلم الآلي..
شفنا البارح RNN
وشفنا كيفاش داير الشكل ديالها ولاش كتصلاح
اليوم غنشوفو كيفاش كتخدم وكتعالج البيانات اللي عندنا
كيما قريتو البارح
الشبكة العصبية المتكررة RNN
هي واحد الشبكة اللي كتاخد الداتا اللي تسلسلية sequential
باش تكون قادرة انها تطبق الذاكرة قصيرة المدى على ديك الداتا
وكتقدر "تحفظ" أجزاء من المدخلات وكتستعملهم باش تعطينا تنبؤات دقيقة.
دبا غنشوفو كيفاش كتخدم:
الشبكة العصبية العادية كتخدم بهاد الطريقة:
1. كناخدو مثال example من شي داتا سيت dataset.
2. الشبكة غاتاخد هاد المثال وتطبق عليه بعض الحسابات المعقدة
باستخدام متغيرات كيتحطو بشكل عشوائي
(هي الأوزان ايلا بقيتي عاقل).
3. غادي تعطينا الnetwork ف output النتيجة المتوقعة.
4. و ايلا درنا مقارنة هاد النتيجة بالقيمة الاصلية الحقيقية غتعطينا داك الخطأ error.
5. كنطبقو backpropagation باش يتضبطو المتغيرات weights.
6. كنبقاو نعاودو الخطوات من 1 إلى 5 حتى نكونو واثقين ونقولو بأن المتغيرات ديالنا محددة ومزيانة.
7. كنديرو التنبؤ من خلال تطبيق هاد المتغيرات على مدخلات جديدة معمرنا مشفناها Test data.
الشبكات العصبية المتكررة RNN حتا هما عندهم بروسيس مشابه،
ولكن باش تفهم الفرق بيناتهم،
غادي نمرو على أبسط نموذج MODEL نقدو نقادو
واللي كيدير التنبؤ بالكلمة التالية ف تسلسل كيعتمد على الكلمات السابقة.
بحال ايلا قلتي لشات جي بي تي.. "كمل ليا هاد الجملة بما يناسب"
أولاً، غادي نحتاجو ندربو الشبكة باستخدام مجموعة بيانات كبيرة.
وفالمثال الذي عندنا..
نقدرو نختارو أي نص كبير (مثلا الكتاب التاريخي "الحرب والسلام" لليو تولستوي).
ملي كنساليو من التدريب TRAINING،
كنجربو ندخلو جملة "كان نابليون إمبراطور ..."
باش نتوقعو تنبؤ معقول بناءً على المعلومات اللي كاينة ف الكتاب.
إذا كيفاش كنبداو؟
كيما شفنا فالخطوات اللي الفوق،
كندخلو مثال واحد ف كل مرة وكننتجو نتيجة واحدة،
وبجوجهم عبارة عن كلمة واحدة.
الاختلاف اللي كيبان بين RNN و بين الشبكة العصبية الاصطناعية
هو انه هنايا غادي نحتاجو أيضًا أننا نعرفو شكاين على المدخلات السابقة قبل تقييم النتيجة.
هنايا تقدر انك تخيل هادوك RNNs بحال شبكات عصبية متعددة التغذية،
كيما قلنا البارح "كتاكل راسها"
وكتدوز المعلومات من شبكة إلى أخرى.
شوف معايا هاد الشيما..
هنايا x_1، x_2، x_3، …، x_t هما الكلمات المدخلة من النص،
ديك y_1، y_2، y_3، …، y_t هما الكلمات التالية المتوقعة..
و h_0، h_1، h_2، h_3، …، h_t بحال ايلا قلتي كارط ميموار..
كتحتفظ بالمعلومات الخاصة بكلمات الإدخال السابقة.
نظرًا لأنه الشبكة العصبية مكتقبلش النص العادي حيت كتعامل غير بالارقام،
اذن غنحتاجو نديرو تشفير الكلمات إلى ارقام او متجهات.
هادي هي vectorization اللي دوينا عليها البارح..
وأفضل طريقة باش تدار هي استخدام تضمينات الكلمات word embeddings
وكنخدمو ب word2vec أو GloVe وغيرهم الكثير...
ولكن هدي غندويو عليها فنهار اخر
باش نديرو التدريب ديال البيانات كنستخدمو هاد القواعد الرياضية..
متخلعوش كل وحدة غنعطيو الاهمية ديالها فالحالة ديالنا
دوك W اللي كتشوف تما هادوك هما الاوزان Weights
ديك h_t كتهز معلومات حول الكلمات السابقة في التسلسل.
وكنحسبوها باستخدام متجه h_(t-1) اللي قبل منو
ومتجه الكلمة الحالي x_t.
دوك 2 متجهات كنديرو ليهم عملية الزائد وكنطبقو عليهم دالة التنشيط غير الخطية f (عادةً tanh أو sigmoid)
ديك y_t كتحسب متجه الكلمات المتوقع ف خطوة زمنية معينة t.
كنخدمو بواحد الدالة سميتها softmax باش نقادو متجه (V,1) يحتوي على جميع العناصر التي يصل مجموعها إلى 1.
وهاد التوزيع الاحتمالي كيعطينا فهرس الكلمة التالية اللي هي اقرب احتمال من المفردات.
هاد J كتحسب لينا واحد النوع من loss function سميتو
cross-entropy loss function ف كل خطوة زمنية
وهدشي باش نحسبو نسبة الخطأ بين الكلمة المتوقعة والفعلية.
فاش كنديرو الtraining ديالنا وكيصدق لينا الاوزان مزيانين،
كيجينا التنبؤ بالكلمة التالية ف الجملة "نابليون كان هو الإمبراطور ديال ..."
واحد الحاجة اللي بطاطا..
عندنا 5 كلمات وبغينا السادسة
ايلا دوزنا كل كلمة ف خطوة زمنية مختلفة من RNN
غيعطينا h_1، h_2، h_3، h_4.
ايلا بغينا الكلمة التالية اللي هي y_5
كنطبقو القاعدة اللولة والثانية باستعمال h_4 وx_5
(هاد x_5 هي متجه الكلمة الخامسة "ديال")
إذا كان التدريب ديالنا ناجح،
فيجب أن نتوقع أن مؤشر index ديال أكبر رقم في y_5
هو نفس مؤشر كلمة "فرنسا" في المفردات اللي عندنا.
وبالتالي غتعطيك فرنسا..
وهاهي الجملة سالات..
هادا هو البلان ديال RNNs
كيبان شوية صعيب.. ولكن الكونصبت ديالو راه غير تمثيل ل كيفاش كيفكر الدماغ ديالك
خلاصة اليوم:
نتلاقاو فايمايل اخر غدا!
كنتمنى تكونو استافدتو.. ايلا عندكم شي تساؤل اولا مشرحتش شي حاجة مزيان، غير صيفط ليا رد فهاد المايل نيت..
— Kaito
ملاحظات:
ايلا عاجبك هدشي وقادر باش تساند هاد newsletter بدعم مادي
دخل لهنا: https://ko-fi.com/callmekaito
شكرا (:
التالي