day 28 - transformer models
(BERT, GPT-4..)
السلام عليكم ورحمة الله... معاكم Kaito :)
مرحبا بيكم فالنهار 28 ديال سلسلة 30 يوم من التعلم الآلي..
البارح ملي دوينا على LLMs
شفنا المحولات Transformers
وكيفاش انها واحد ن اهم المكونات ديال GPT
ديك T هي نيت Transformers
دبا غنشوفو كيفاش كيخدمو وشنو كيميزهم على الاخرين

شحال هادي كان الذكاء الاصطناعي حاضر فالترجمة والمهام البساط..
ولكن البلان ديال انه نقدر ندوي معاه ويفهمني ويجاوب على اي سؤال
داكشي كان مزال حلم.. وكنا غير كنضحكو بيه وكنشوفوه فافلام هوليوود و دوزيم
كانت الحياة عادية قبل 2017
ملي خرجات Google واحد ورقة بحث بعنوان "الانتباه هو كل ما تحتاجه"،
"Attention is all you need"

وفيها بان هاد الكونصبت اللي غير العالم 180 درجة
واللي هو Transformers
اللي لعب دور فعال باش يخرجو منو الناس تطبيقات وادوات كيديرو العجب
من ChatGPT ل Bard ل Midjourney ل Sora
اضافة لادوات اخرى ومودلز كيتقادو كل نهار مبازيين على بنية Transformers
فشناهما هاد Transformers؟
باش متدهشرش..
راه هاد المحول ما هو الا نوع من الشبكات العصبية
اللي كتعلم السياق ديال البيانات المتسلسلة
وكتولد بيانات جديدة منها.
فالاول كانت تطورات باش تحل الشكل ديال الترجمة الالية العصبية.
ولكن هدفها الرئيسي ف معالجة اللغة الطبيعية:
هو فهم سياق الكلمات في الجملة.
قبل مايكونو المحولات،
كانو RNNs و LSTMs كيديرو الخدمة ديال معالجة البيانات النصية.
هاد المودلز كيقراو النص بشكل تسلسلي،
كلمة وحدة ف كل مرة،
وكتهز بعض المعلومات من الكلمات السابقة إلى الكلمات التالية.
وهدشي كيخليهم يفهمو شوية ديال السياق context،
ولكن المشكل ديالهم هو فالجمل الطويلة
حيتاش المعلومات اللي شاف فالكلمات الاولين
يقدرو ينقصو أولا يضيعو مع غيوصلو لمعالجة نهاية الجملة.
مثلا عندنا جملة "المشة , اللي ديجا كلات الحوتة , نعسات على ….."
حيتاش الجملة قصيرة غتجيهم ساهلة يتوقعو انها مثلا "الكرسي"
حيتاش المشاش غالبا كينعسو على الحصيرة على الارض على الكرسي الخ..
ولكن تخيل عندي جملة كبيرة وتحطيت فنفس الموقف..
غدي يتوقع بلي الكلمة التالية غتمعني على الحوتة..
وغتتوقع كلمة "الماء" او شي كلمة اخرى متعلقة بالحوتة..
وهذا خطأ حيتاش المودل معندوش السياق كامل بحكم انه خسر المعلومات ديال الكلمات الاولين.
المحولات ديالنا جاو باش يحلو هاد المشكلة.
اللي زايد فهاد Transformers
هو انهم كيخدمو بواحد الآلية كتسمى "الانتباه Attention"
"الانتباه" كتساعد النموذج على تحديد أجزاء بيانات الإدخال input المهمة
وخصنا "نعطيوها كامل الانتباه" عند انشاء المخرجات output
هكا كيقدر يفهم السياق ديال كل كلمة وعلاقتها مع جميع الكلمات الأخرى،
بغض النظر على التباعد ديالهم في الجملة.
نعطيك واحد المثال:
تخيل معايا أنك كاتقرا شي مقالة طويلة أو كتاب.
ناخدو غير هاد المايل اللي كتقرا ديما..
نتايا مكتعطيش اهتمام متساوي لكل كلمة أو جملة.
بعض الأجزاء أكثر أهمية باش تفهم الفكرة الرئيسية،
والبعض الآخر أقل أهمية.
مثلا تقدر تركز أكثر على المقدمة وخلاصة اليوم فالخاتمة,
وبدرجة أقل على الأمثلة او بلاصة المصادر.
هادا هو نفس الكونسبت ديال الانتباه ف نماذج Transformers.
نتايا عطيتي الانتباه ديالك لاهم الكلمات والجمل
وفنفس الوقت حافظتي على السياق وقدرتي تفهم المايل كامل.
وهذا راه تحسن كبير مقارنة بـ RNNs وLSTMs،
خصوصا بالنسبة لمهام بحال الترجمة
فاش كيكون الفهم ديال السياق الكامل ضروري جدا.
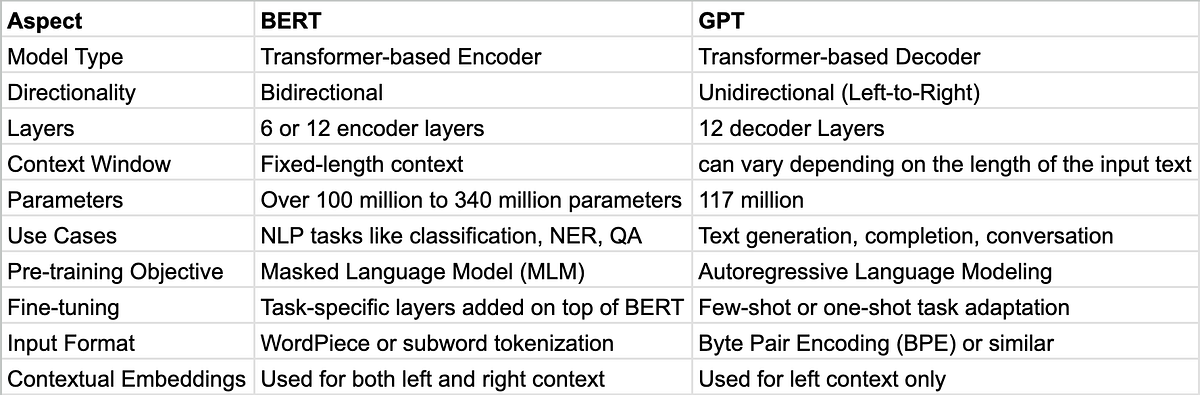
هاد BERT وGPT بجوجهم نموذجين كيعتامدو على المحولات،
ولكن كيختالفو ف الاتجاه وأهداف التدريب.


وهادا جدول فيه الفروقات بين هاد المودلز
ولكن مناش كيتكون هاد Transformer أصلا؟
باش نفهمو البنية ديال هاد النوع من المودلز
ناخدو مثال ديال محول مخصص للترجمة ديال اللغات
داير بحال شي مكينة فشي مصنع
كتدخل ليه نص.. وكيجي المحول و"كيحولو" لنص بلغة اخرى
دكشي علاش أصلا تسمى "محول"

وإيلا تعمقنا شي شوية غنلاحظو بلي transformer كيتكون من جزءين رئيسيين:
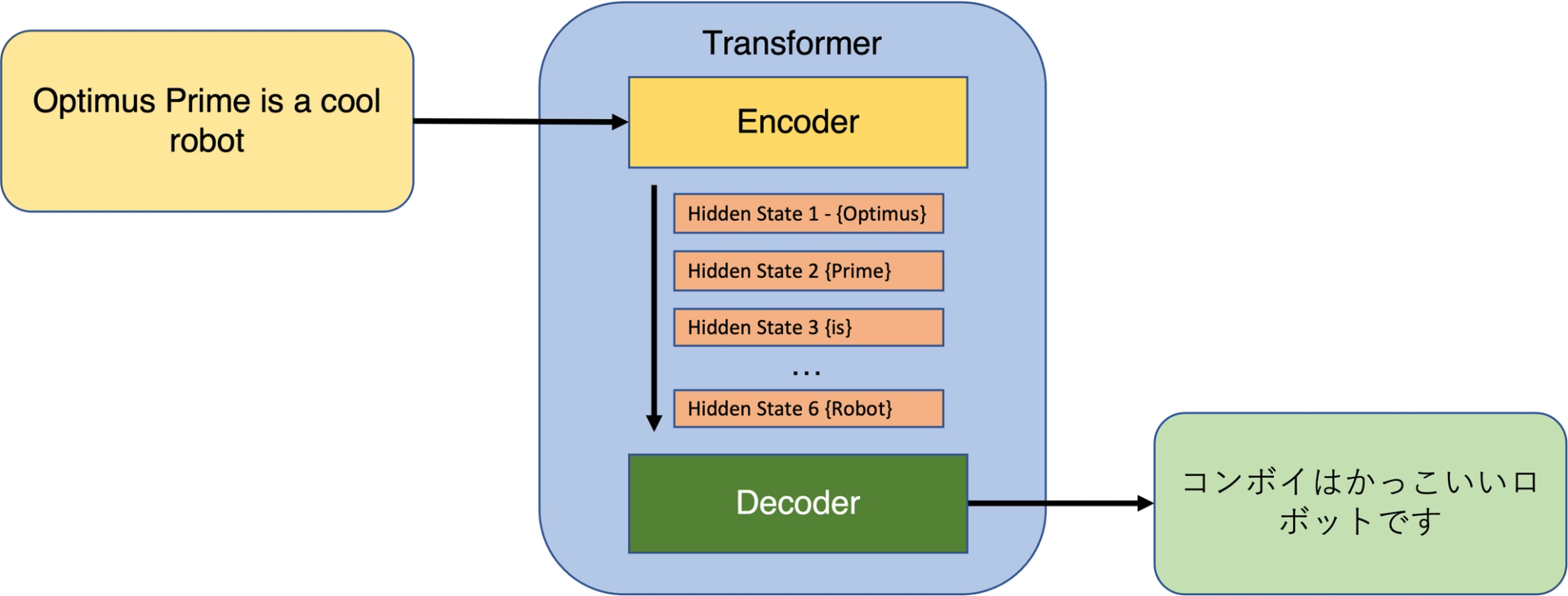
المشفر Encoder ومفكك التشفير Decoder
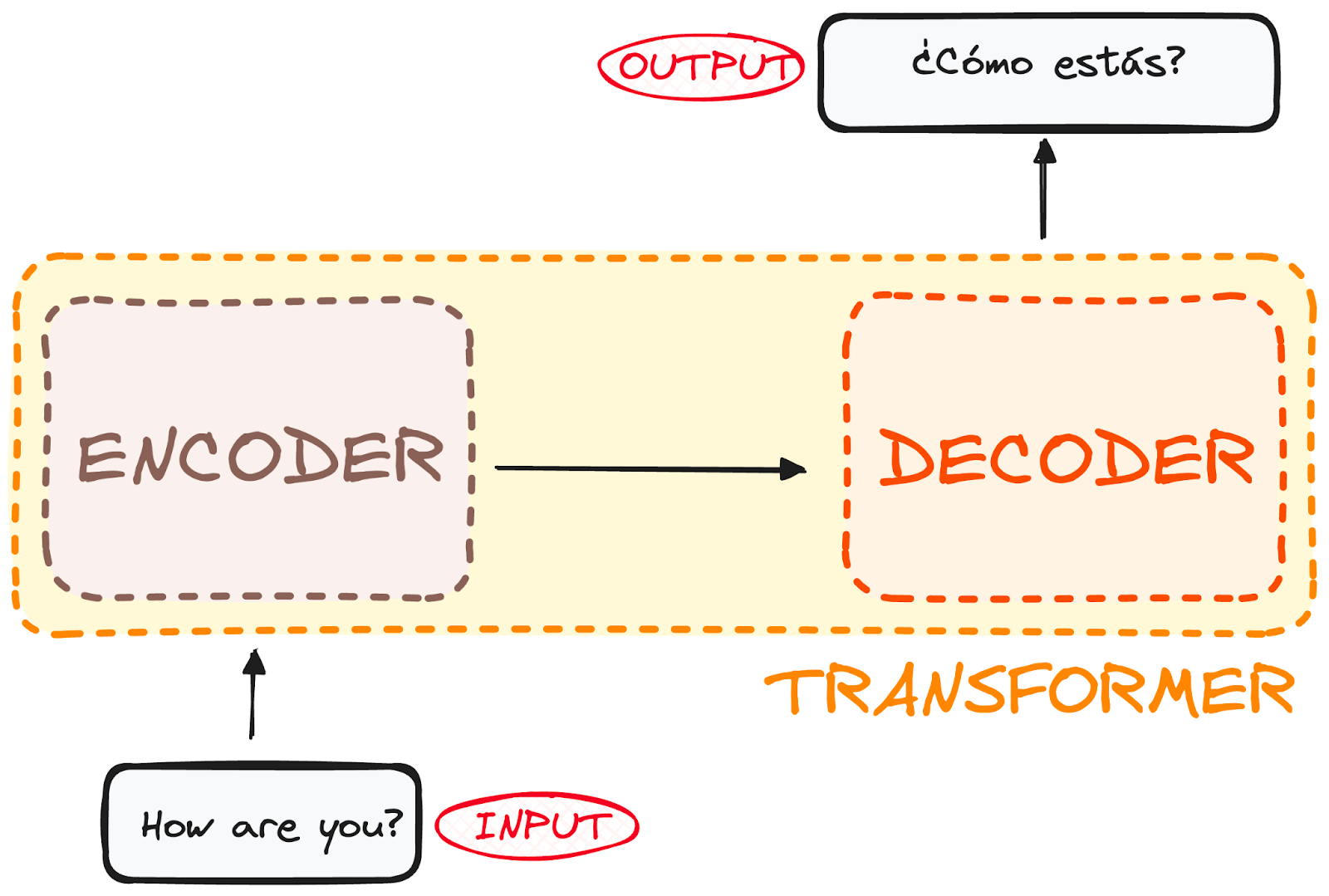
المشفر كياخذ المدخلات ديالنا وكيردهم على شكل مصفوفة Matrix representation لداك الإدخال.
وهدشي باستعمال واحد البروسيس
كيتسمى embedding and positional encoding
واللي ديجا شفناهم فالايام اللي دازو
مفكك التشفير كاياخذ داك التمثيل المصفوفي المشفر اللي خرجو المشفر
وكيقوم بإنشاء مخرجات بشكل متكرر.
باش نفهمو كثر غنشرحو كل جزء:
المشفر The Encoder:
مهمة المشفر هي فهم جملة الإدخال.
كيقرا الجملة وكيحولها ل مجموعة من المفاتيح والقيم.
keys and values
هاد المفاتيح والقيم كتاخذ المعنى ديال الجملة بالطريقة اللي يمكن تفهمها الآلة.
هاد المشفر كيدير هاد الخدمة باستخدام الطبقات.
كل طبقة فيها جزءين:
1 . طبقة الانتباه الذاتي Self-Attention Layer:
هاد الجزء كيعاون Encoder انه يفهم الأهمية ديال كل كلمة في الجملة بالنسبة لجميع الكلمات الأخرى.
بحال فاش كتقرا جملة وكتفهم أن بعض الكلمات
(مثل الأسماء أو الأفعال)
كتكون عندها أهمية اكثر من غيرها
(مثل "the" أو "an").
2 . الشبكة العصبية الاصطناعية Feed Forward Neural Network:
هاد الجزء عبارة عن شبكة عصبية بسيطة كتعالج كل كلمة (مع "الانتباه" ديالها) بشكل منفصل.
مفكك التشفير The Decoder:
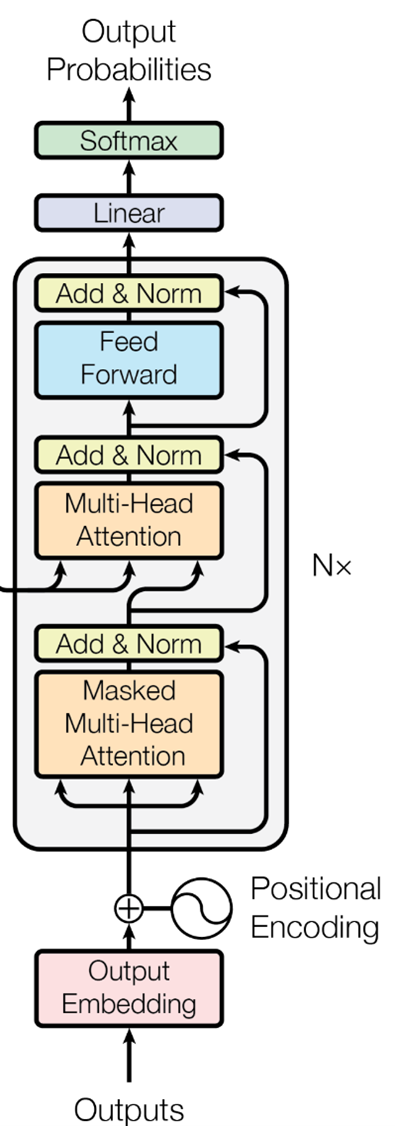
الهدف ديال مفكك التشفير هو ياخذ المفاتيح والقيم اللي جاو من المشفر Encoder
ويحولهم إلى الجملة المترجمة.
وحتاهو عندو طبقات ديالو،
ولكن كل طبقة فيها ثلاثة أجزاء:
1 . طبقة الانتباه الذاتي Self-Attention Layer:
دايرة بحال هاديك اللي شفنا فال Encoder،
ولكن كتشوف غير ف دوك الكلمات اللي كاينين في الجملة الناتجة التي خرجات حتال دبا ف output.
يعني ملي كيشوف الجملة ملي كتترجم كلمة تابعة الاخرى..
مثلا خرج لينا ف output أول 2 كلمات..
ملي غيبغي يجينيري الكلمة الثالثة..
خصو يشوف ويعتبر غير دوك 2 كلمات اللي خرجو ليه..
ميشوفش هو الكلمات الجايين اللي غيتترجمو..
حيتاش معارفهومش اصلا..
دكشي علاش قلنا كيشوف غير فدكشي اللي خرج وصافي
مكيشوفش المستقبل ديال الكلمات اللي غيخرجو
حيتاش مزال معارف اشمن كلمات غادي يخرجو
هاد اللعيبة كتسمى Auto-regressive property
ودكشي علاش ايضا تسمى Masked..
2 . طبقة انتباه المشفر ومفكك التشفير Encoder-Decoder Attention Layer:
هاد الجزء كيخليك ترجع لدوك المفاتيح والقيم من Encoder.
بحال فاش كتبغي تكتب شي ملخص ديال شي درس
وكتحتاج ترجع للملاحظات ديالك notes باش تأكد أنك دويتي على جميع النقاط المهمة.
"اشهار: ايلا كنتي طالب وبغيتي تعرف كيفاش تكتب notes مزيانين فقرايتك
راني لحت واحد الفيديو فيوتيوب تفرج فيه دكشي مفيد جدا"
3 . الشبكة العصبية الاصطناعية Feed Forward Neural Network:
نفس الحاجة اللي كادير في Encoder.
فاللخر،
مفكك التشفير كيخرج لينا الجملة المترجمة، كلمة واحدة في كل مرة.
(كيما قلنا البارح على ChatGPT فاش كيبان ليك الجواب كيتكتب كلمة بكلمة)
هاد العملية كاملة كتخلي Transformer انه يترجم الجمل
و يلتقط المعنى والسياق ديال كل كلمة،
كيفما كان المدى ديال تباعد الكلمات في الجملة.
وهاد Encoder و Decoder كيعطيونا..
Transformer!!

بطبيعة الحال.. ماشي غير هادشي اللي فيه
كاين اعمق من هدشي و مفاهيم اخرين
ولكن كيما كنقولو ديما: "This is NOT a course"
ايلا بغيتي فيديو كيدوي على Transformers بطريقة زوينة ومتعمقة
تفرج فهاد الفيديو (شكرا لفقيه البيانات طه بوحسين على الاقتراح الرائع)
وهذا فيديو اخر كيشرحو بطريقة رياضية مبسطة
خلاصة اليوم:

نتلاقاو فايمايل اخر غدا!
كنتمنى تكونو استافدتو.. ايلا عندكم شي تساؤل اولا مشرحتش شي حاجة مزيان، غير صيفط ليا رد فهاد المايل نيت..
— Kaito
ملاحظات:
ايلا عاجبك هدشي وقادر باش تساند هاد newsletter بدعم مادي
دخل لهنا: https://ko-fi.com/callmekaito
شكرا (:

السلام عليكم ورحمة الله... معاكم Kaito :)
مرحبا بيكم فالنهار 28 ديال سلسلة 30 يوم من التعلم الآلي..
البارح ملي دوينا على LLMs
شفنا المحولات Transformers
وكيفاش انها واحد ن اهم المكونات ديال GPT
ديك T هي نيت Transformers
دبا غنشوفو كيفاش كيخدمو وشنو كيميزهم على الاخرين
شحال هادي كان الذكاء الاصطناعي حاضر فالترجمة والمهام البساط..
ولكن البلان ديال انه نقدر ندوي معاه ويفهمني ويجاوب على اي سؤال
داكشي كان مزال حلم.. وكنا غير كنضحكو بيه وكنشوفوه فافلام هوليوود و دوزيم
كانت الحياة عادية قبل 2017
ملي خرجات Google واحد ورقة بحث بعنوان "الانتباه هو كل ما تحتاجه"،
"Attention is all you need"
وفيها بان هاد الكونصبت اللي غير العالم 180 درجة
واللي هو Transformers
اللي لعب دور فعال باش يخرجو منو الناس تطبيقات وادوات كيديرو العجب
من ChatGPT ل Bard ل Midjourney ل Sora
اضافة لادوات اخرى ومودلز كيتقادو كل نهار مبازيين على بنية Transformers
فشناهما هاد Transformers؟
باش متدهشرش..
راه هاد المحول ما هو الا نوع من الشبكات العصبية
اللي كتعلم السياق ديال البيانات المتسلسلة
وكتولد بيانات جديدة منها.
فالاول كانت تطورات باش تحل الشكل ديال الترجمة الالية العصبية.
ولكن هدفها الرئيسي ف معالجة اللغة الطبيعية:
هو فهم سياق الكلمات في الجملة.
قبل مايكونو المحولات،
كانو RNNs و LSTMs كيديرو الخدمة ديال معالجة البيانات النصية.
هاد المودلز كيقراو النص بشكل تسلسلي،
كلمة وحدة ف كل مرة،
وكتهز بعض المعلومات من الكلمات السابقة إلى الكلمات التالية.
وهدشي كيخليهم يفهمو شوية ديال السياق context،
ولكن المشكل ديالهم هو فالجمل الطويلة
حيتاش المعلومات اللي شاف فالكلمات الاولين
يقدرو ينقصو أولا يضيعو مع غيوصلو لمعالجة نهاية الجملة.
مثلا عندنا جملة "المشة , اللي ديجا كلات الحوتة , نعسات على ….."
حيتاش الجملة قصيرة غتجيهم ساهلة يتوقعو انها مثلا "الكرسي"
حيتاش المشاش غالبا كينعسو على الحصيرة على الارض على الكرسي الخ..
ولكن تخيل عندي جملة كبيرة وتحطيت فنفس الموقف..
غدي يتوقع بلي الكلمة التالية غتمعني على الحوتة..
وغتتوقع كلمة "الماء" او شي كلمة اخرى متعلقة بالحوتة..
وهذا خطأ حيتاش المودل معندوش السياق كامل بحكم انه خسر المعلومات ديال الكلمات الاولين.
المحولات ديالنا جاو باش يحلو هاد المشكلة.
اللي زايد فهاد Transformers
هو انهم كيخدمو بواحد الآلية كتسمى "الانتباه Attention"
"الانتباه" كتساعد النموذج على تحديد أجزاء بيانات الإدخال input المهمة
وخصنا "نعطيوها كامل الانتباه" عند انشاء المخرجات output
هكا كيقدر يفهم السياق ديال كل كلمة وعلاقتها مع جميع الكلمات الأخرى،
بغض النظر على التباعد ديالهم في الجملة.
نعطيك واحد المثال:
تخيل معايا أنك كاتقرا شي مقالة طويلة أو كتاب.
ناخدو غير هاد المايل اللي كتقرا ديما..
نتايا مكتعطيش اهتمام متساوي لكل كلمة أو جملة.
بعض الأجزاء أكثر أهمية باش تفهم الفكرة الرئيسية،
والبعض الآخر أقل أهمية.
مثلا تقدر تركز أكثر على المقدمة وخلاصة اليوم فالخاتمة,
وبدرجة أقل على الأمثلة او بلاصة المصادر.
هادا هو نفس الكونسبت ديال الانتباه ف نماذج Transformers.
نتايا عطيتي الانتباه ديالك لاهم الكلمات والجمل
وفنفس الوقت حافظتي على السياق وقدرتي تفهم المايل كامل.
وهذا راه تحسن كبير مقارنة بـ RNNs وLSTMs،
خصوصا بالنسبة لمهام بحال الترجمة
فاش كيكون الفهم ديال السياق الكامل ضروري جدا.
هاد BERT وGPT بجوجهم نموذجين كيعتامدو على المحولات،
ولكن كيختالفو ف الاتجاه وأهداف التدريب.
وهادا جدول فيه الفروقات بين هاد المودلز
ولكن مناش كيتكون هاد Transformer أصلا؟
باش نفهمو البنية ديال هاد النوع من المودلز
ناخدو مثال ديال محول مخصص للترجمة ديال اللغات
داير بحال شي مكينة فشي مصنع
كتدخل ليه نص.. وكيجي المحول و"كيحولو" لنص بلغة اخرى
دكشي علاش أصلا تسمى "محول"
وإيلا تعمقنا شي شوية غنلاحظو بلي transformer كيتكون من جزءين رئيسيين:
المشفر Encoder ومفكك التشفير Decoder
المشفر كياخذ المدخلات ديالنا وكيردهم على شكل مصفوفة Matrix representation لداك الإدخال.
وهدشي باستعمال واحد البروسيس
كيتسمى embedding and positional encoding
واللي ديجا شفناهم فالايام اللي دازو
مفكك التشفير كاياخذ داك التمثيل المصفوفي المشفر اللي خرجو المشفر
وكيقوم بإنشاء مخرجات بشكل متكرر.
باش نفهمو كثر غنشرحو كل جزء:
المشفر The Encoder:
مهمة المشفر هي فهم جملة الإدخال.
كيقرا الجملة وكيحولها ل مجموعة من المفاتيح والقيم.
keys and values
هاد المفاتيح والقيم كتاخذ المعنى ديال الجملة بالطريقة اللي يمكن تفهمها الآلة.
هاد المشفر كيدير هاد الخدمة باستخدام الطبقات.
كل طبقة فيها جزءين:
1 . طبقة الانتباه الذاتي Self-Attention Layer:
هاد الجزء كيعاون Encoder انه يفهم الأهمية ديال كل كلمة في الجملة بالنسبة لجميع الكلمات الأخرى.
بحال فاش كتقرا جملة وكتفهم أن بعض الكلمات
(مثل الأسماء أو الأفعال)
كتكون عندها أهمية اكثر من غيرها
(مثل "the" أو "an").
2 . الشبكة العصبية الاصطناعية Feed Forward Neural Network:
هاد الجزء عبارة عن شبكة عصبية بسيطة كتعالج كل كلمة (مع "الانتباه" ديالها) بشكل منفصل.
مفكك التشفير The Decoder:
الهدف ديال مفكك التشفير هو ياخذ المفاتيح والقيم اللي جاو من المشفر Encoder
ويحولهم إلى الجملة المترجمة.
وحتاهو عندو طبقات ديالو،
ولكن كل طبقة فيها ثلاثة أجزاء:
1 . طبقة الانتباه الذاتي Self-Attention Layer:
دايرة بحال هاديك اللي شفنا فال Encoder،
ولكن كتشوف غير ف دوك الكلمات اللي كاينين في الجملة الناتجة التي خرجات حتال دبا ف output.
يعني ملي كيشوف الجملة ملي كتترجم كلمة تابعة الاخرى..
مثلا خرج لينا ف output أول 2 كلمات..
ملي غيبغي يجينيري الكلمة الثالثة..
خصو يشوف ويعتبر غير دوك 2 كلمات اللي خرجو ليه..
ميشوفش هو الكلمات الجايين اللي غيتترجمو..
حيتاش معارفهومش اصلا..
دكشي علاش قلنا كيشوف غير فدكشي اللي خرج وصافي
مكيشوفش المستقبل ديال الكلمات اللي غيخرجو
حيتاش مزال معارف اشمن كلمات غادي يخرجو
هاد اللعيبة كتسمى Auto-regressive property
ودكشي علاش ايضا تسمى Masked..
2 . طبقة انتباه المشفر ومفكك التشفير Encoder-Decoder Attention Layer:
هاد الجزء كيخليك ترجع لدوك المفاتيح والقيم من Encoder.
بحال فاش كتبغي تكتب شي ملخص ديال شي درس
وكتحتاج ترجع للملاحظات ديالك notes باش تأكد أنك دويتي على جميع النقاط المهمة.
"اشهار: ايلا كنتي طالب وبغيتي تعرف كيفاش تكتب notes مزيانين فقرايتك
راني لحت واحد الفيديو فيوتيوب تفرج فيه دكشي مفيد جدا"
3 . الشبكة العصبية الاصطناعية Feed Forward Neural Network:
نفس الحاجة اللي كادير في Encoder.
فاللخر،
مفكك التشفير كيخرج لينا الجملة المترجمة، كلمة واحدة في كل مرة.
(كيما قلنا البارح على ChatGPT فاش كيبان ليك الجواب كيتكتب كلمة بكلمة)
هاد العملية كاملة كتخلي Transformer انه يترجم الجمل
و يلتقط المعنى والسياق ديال كل كلمة،
كيفما كان المدى ديال تباعد الكلمات في الجملة.
وهاد Encoder و Decoder كيعطيونا..
Transformer!!
بطبيعة الحال.. ماشي غير هادشي اللي فيه
كاين اعمق من هدشي و مفاهيم اخرين
ولكن كيما كنقولو ديما: "This is NOT a course"
ايلا بغيتي فيديو كيدوي على Transformers بطريقة زوينة ومتعمقة
تفرج فهاد الفيديو (شكرا لفقيه البيانات طه بوحسين على الاقتراح الرائع)
وهذا فيديو اخر كيشرحو بطريقة رياضية مبسطة
خلاصة اليوم:
نتلاقاو فايمايل اخر غدا!
كنتمنى تكونو استافدتو.. ايلا عندكم شي تساؤل اولا مشرحتش شي حاجة مزيان، غير صيفط ليا رد فهاد المايل نيت..
— Kaito
ملاحظات:
ايلا عاجبك هدشي وقادر باش تساند هاد newsletter بدعم مادي
دخل لهنا: https://ko-fi.com/callmekaito
شكرا (:
التالي